Attention(注意力机制)
- Attention for Image
- Attention for Machine Translation
- Self-Attention
没有image-Attention:看图说话

整个网络属于分类任务。
Question:为什么不采用最后一层?
因为最后一层缺乏泛化能力(Lack of generalization capability) 
LSTM部分
将CNN全连接层(FC4096)获得的向量称为v,通过线性转换获得矩阵Wih,引入LSTM网络中,获得函数:
同时,通过函数获得一个分布输出,得到概率最大值。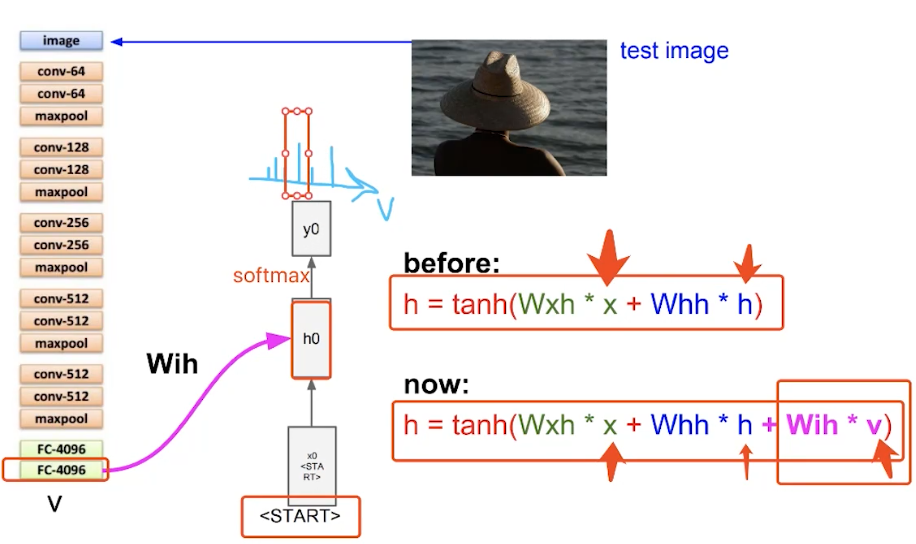
循环训练模型
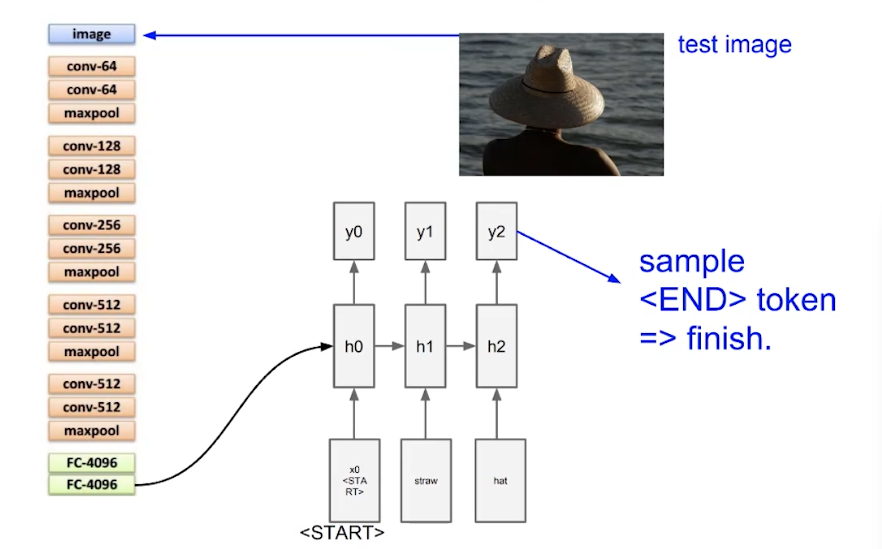
缺陷!!!
- 错误叠加 如果某一部分错误,那后面也会错误
- Debug:错误在哪里? 上述方法生成的每一个描述,依赖于上一描述。
- 图像中的多个对象可能输出不同结果
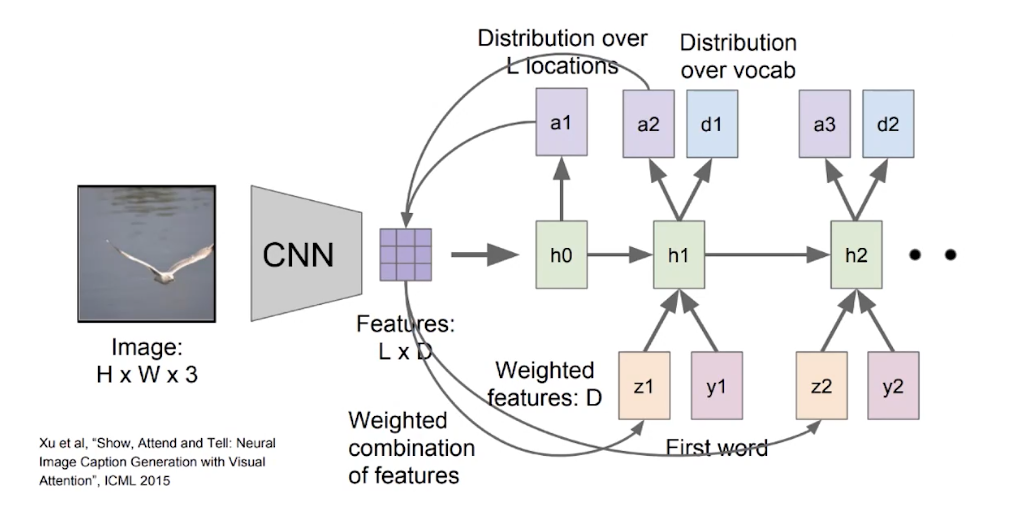
image-Attention:看图说话
将注意力集中到图像中的某个或某几个对象,从而提高准确度。 
大致流程
图片 -> CNN ->分为个区域,每个区域提取特征向量D -> 非线性转换f获得-> 获得表示相关性: 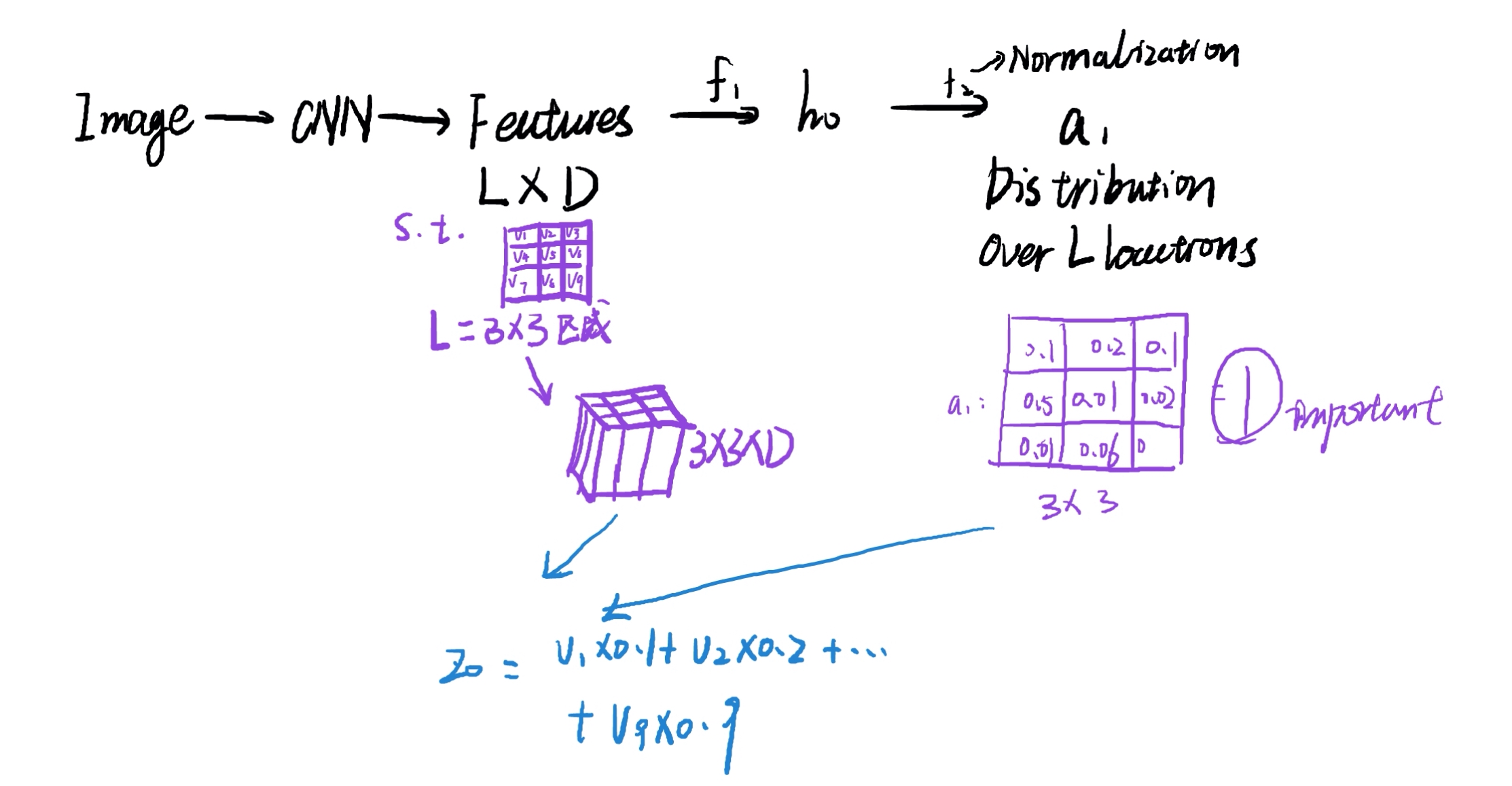
是加权平均值
完整表示生成第一个单词:
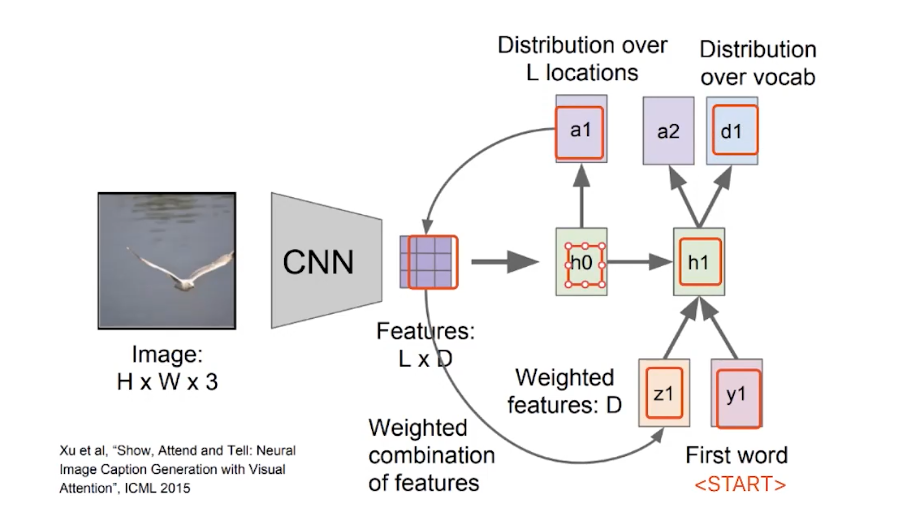
生成所有单词:
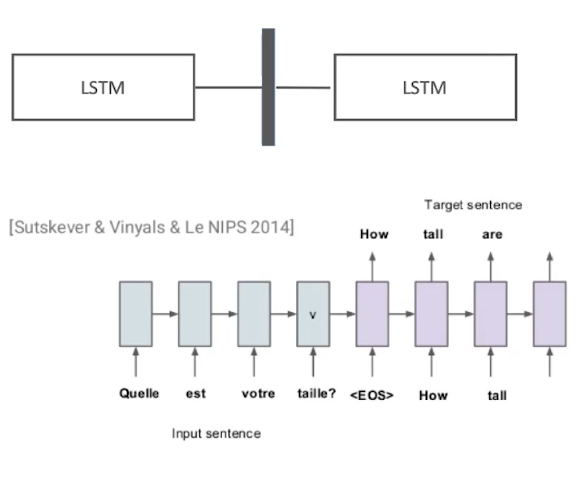
No attendtion:机器翻译-Seq2Seq模型
缺陷:
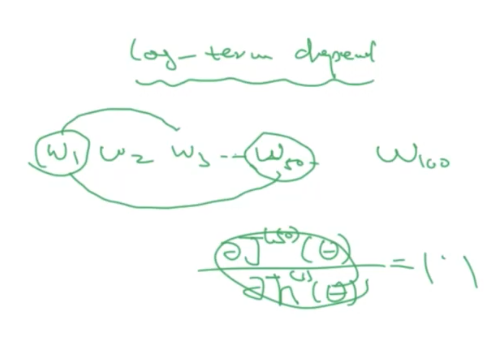
- Long-term Dependence 可以捕获短时间的关系,但是长时间的关系无法捕获。例如可以捕获,但是难以捕获。在利用梯度下降的方法进行计算的是时候,很容易出现梯度爆炸或者梯度消失。
所以长句子的翻译通常不是很准确 - bottleneck problem 在Multimodel Learning中的中间向量来自左侧的输出结果,但是中间向量直接影响输出结果,所以中间向量被称为bottleneck
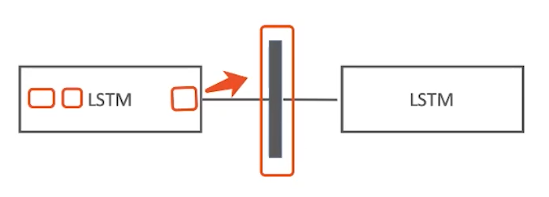
一但中间向量出现问题,那么后面就出现输出错误。这个问题称为bottlenect problem - 注意力较差,可解释性较差。
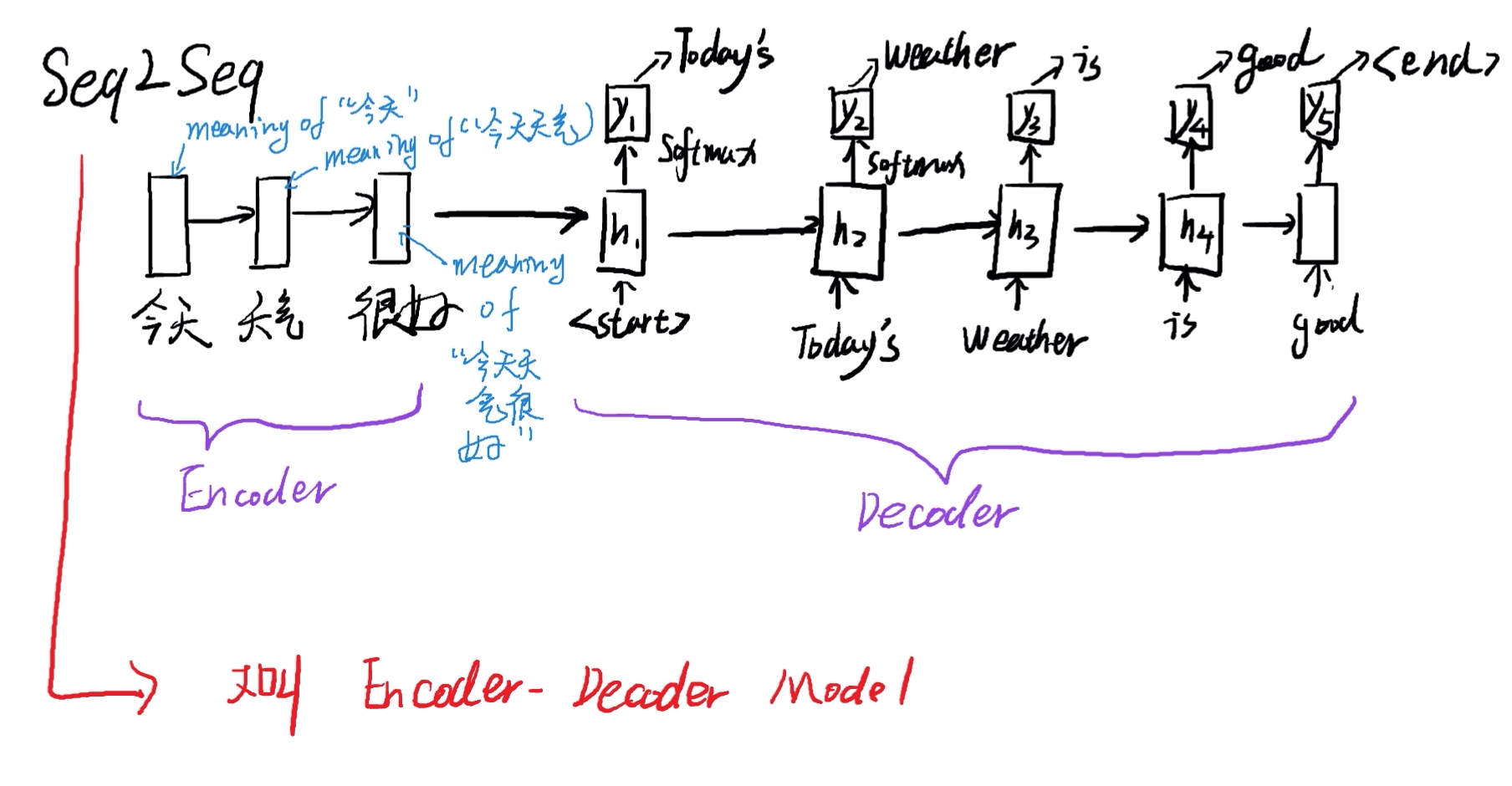
Attention:机器翻译-Seq2Seq模型
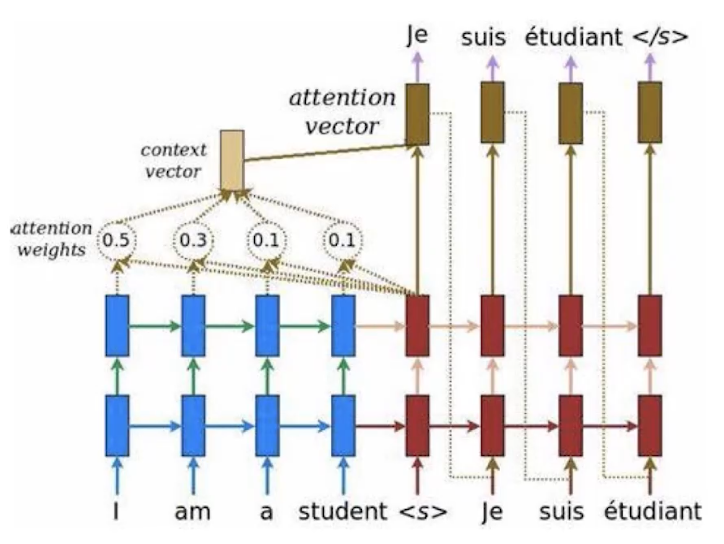
大致流程
Encoder 部分变化不大,但是在生成第一个单词的时候,要将注意力放在第一个词。
那么How to do it?
分别计算与的内积:获得:score:然后通过Normalization获得一个和为1的权重向量,求加权平均数: 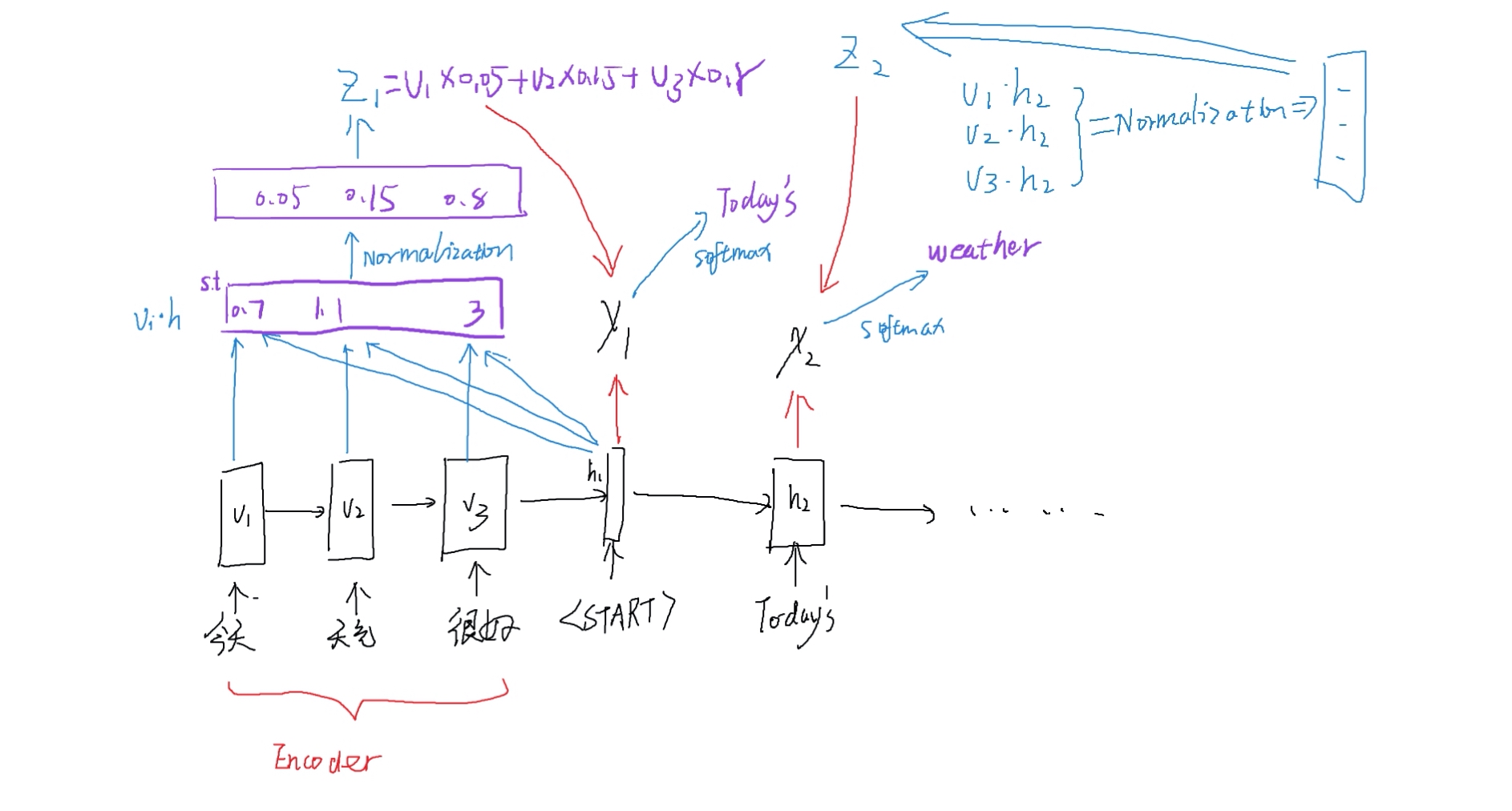
Self-Attention
Transformer
时序模型必然存在梯度问题。我们尝试使用非时序类模型来实现时序模型的特点,即捕获相关性。 Transformer是深度学习模型,纵向深度很深。Transformer也是一个Encoder-Decoder模型。 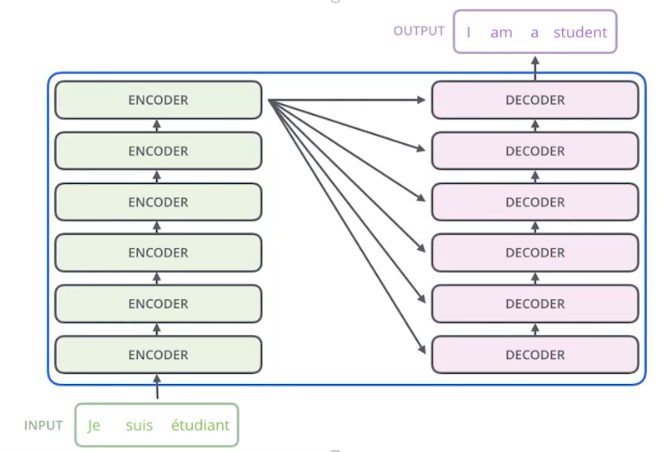
拆分可分为: 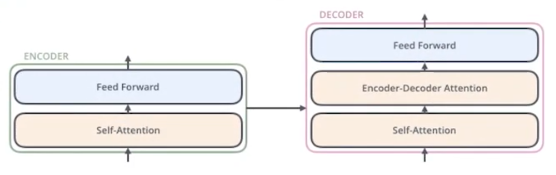
Feed Forward负责非线性转换,Self-Attention是关键。
Self-Attention详解
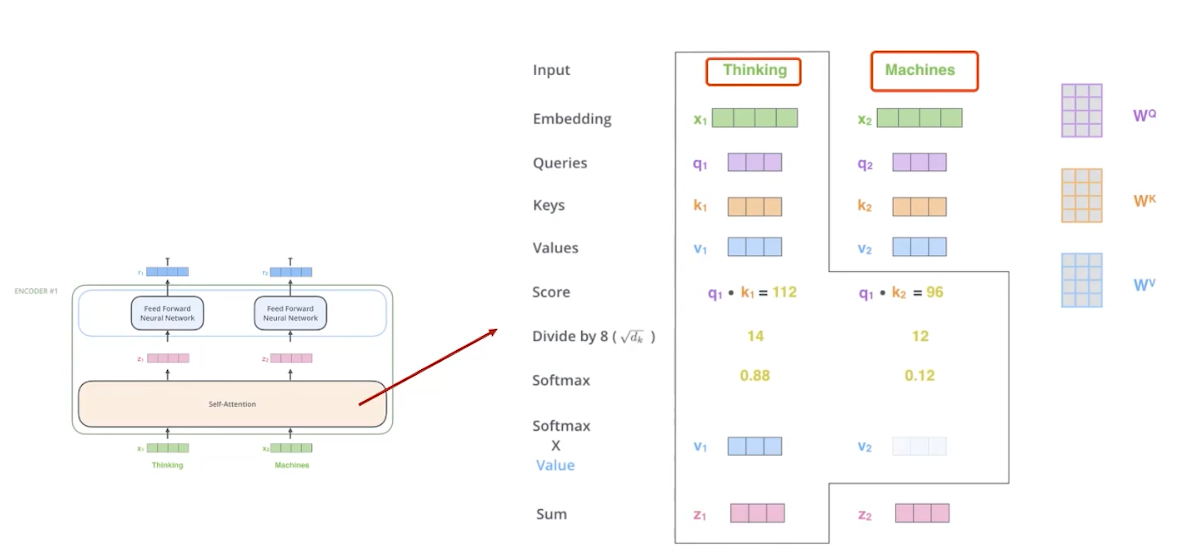
代表的是输入的Embedding,定义了三个不同矩阵,那么。
我们需要捕获不同单词之间的dependence,所以我们需要计算当前单词与其他单词的相关性,即使用当前单词的Queries分别与当前的词的Keys和其他单词的Keys求内积获得Score。 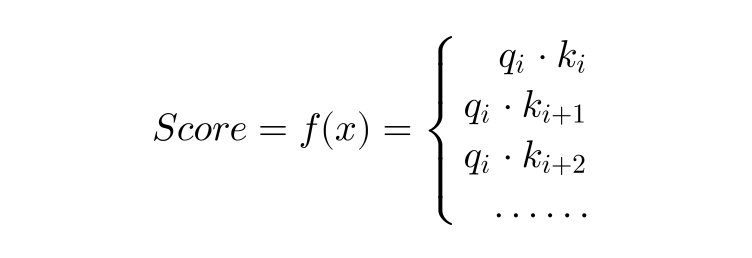
Score通过Normalization获得权值和为1的多个值。然后通过每个值分别与Values求加权平均值获得
为什么在归一化之前要除以。是一个实验值,是向量的纬度,直接获得的Score值较大,直接通过softmax转换会使差距过大,导致部分权值失效。
通过这样的计算,可以获得某个单词与其他单词的关系: 
颜色越深表示关系Score值越大,则关系越深。显然,“It"指的是"animal”,所以"animail"颜色最深。



