Background
分别使用CNN和LSTM对图像和文字进行处理: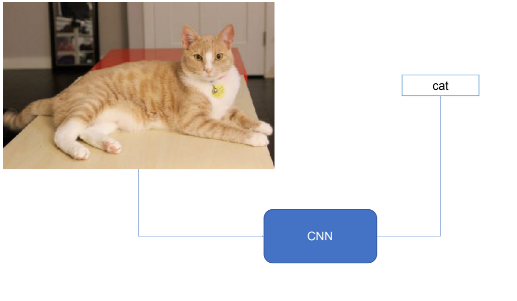
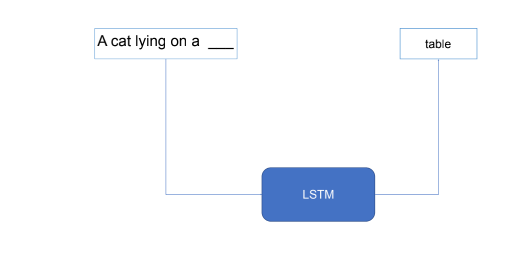
将两个神经网络结合: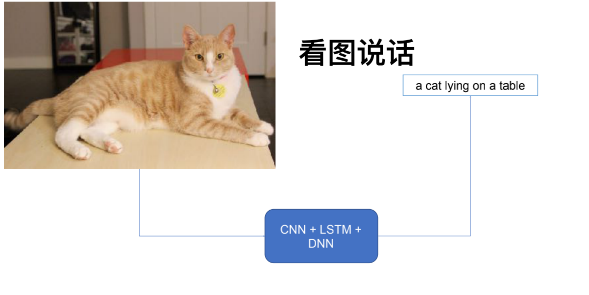
应用领域
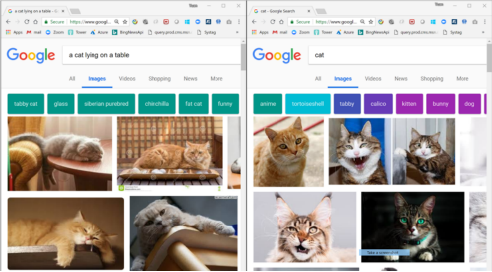
图像搜索
安全

鉴黄

涉猎知识
- 数字图像处理
- 图像读取
- 图像缩放
- 图像数据纬度变换
- 自然语言处理
- 文字清洗
- 文字嵌入(Embedding)
- CNN卷积神经网络
- 图像特征提取
- 迁移学习(Transfer Learning)
- LSTM递归神经网络
- 文字串(sequence)特征提取
- DNN深度神经网络
- 从图像特征和文字串(sequence)的特征预测下一个单词
使用数据集
Framing Image Description as a Ranking Task:Data, Models, and Evaluation Metrics,2013.
- Flickr8K
- 8000个图像,每幅图5个标题,描述图像里面的事物和事件
- 不包含著名人物和地点
- 分为3个集合:6000个训练图像,1000个开发图像,1000个测试图像
数据示例

- A child in a pink dress is climbing up a set of stairs in an entry way.
- A girl going into a wooden building .
- A little girl climbing into a wooden playhouse.
- A little girl climbing the stairs to her playhouse.
- A little girl in a pink dress going into a wooden cabin
目标
自动生成英文标题,与人类生成的标题越相似越好。
衡量两个句子的相似度(BLEU),一个句子与其他几个句子的相似度(Corpus BLEU)
- BLEU:Bilingual Evaluation Understudy(双语评估替换)。
- BLEU是一个比较候选文本翻译与其他一个或多个参考翻译的评价分数。尽管他是为翻译工作而开发的,但是仍然可以用于评估自动生成的文本质量
VGG16网络模型
Very Deep Convplutional Networks For Large-Scale Visual Recognition
- Pre-trained model:Oxford Visual Geometry Group赢得2014ImageNet竞赛
- 用于图像分类,讲输入图像分为1000个类别
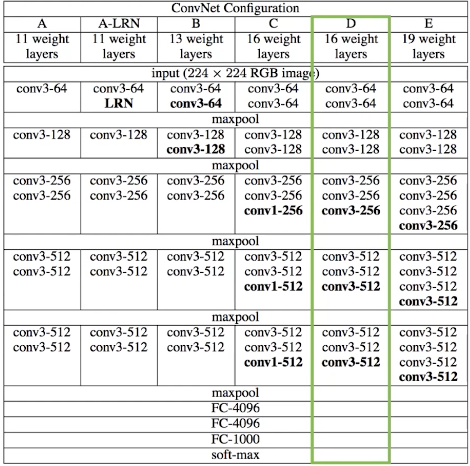
绿色标注为VGG网络。可以看出,该网络有16个权值层,5个池化层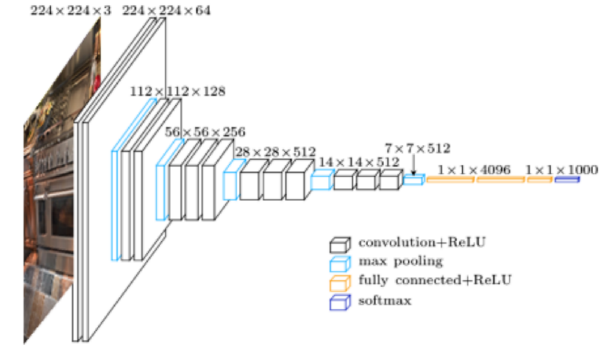
编写代码实现网络(练习)
准备框架
1 | from keras.models import Sequential |
编辑输入
VGG16输入为(224,224,RGB)的图像
1 | input_shape = (224, 224, 3) |
部分网络结构
1 | model = Sequential([ |
Maxpooling层和全连接层之间要使用Flatten。
总代码为:
1 | from keras.models import Sequential |
运行可见输出: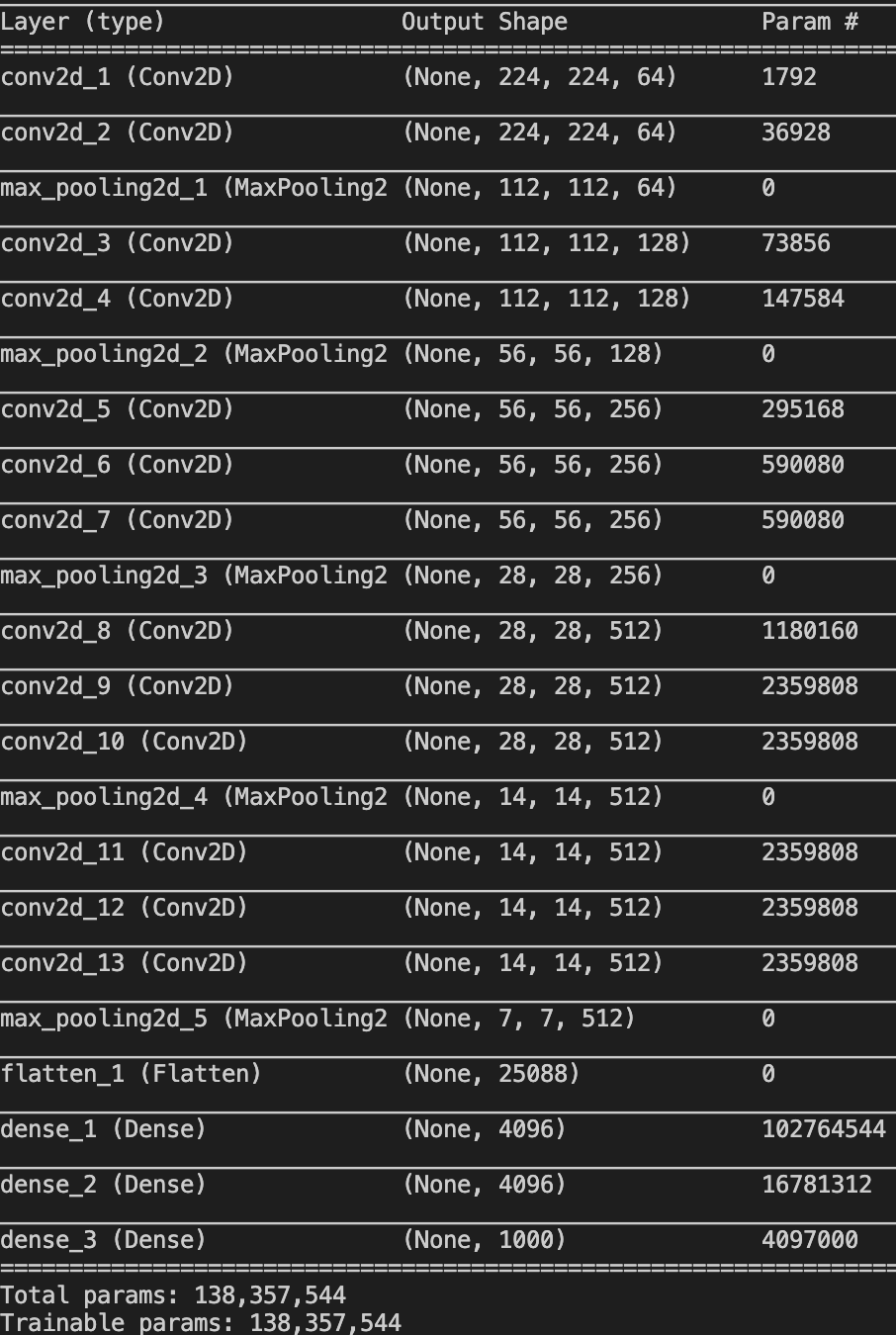
看图说话项目
本项目所需的所有数据集和网络如下:
链接:https://pan.baidu.com/s/1nP856AdlTmcRSPez2–u5A
密码:vs7b
图像特征提取
将flicker8K的图像文件转为图像特征,保存为字典pickle文件
- 从给定的VGG16网络结构文件(JS文件)和网络权值文件,创建VGG16网络
- 修改网络结构(去除最后一层)
- 利用修改的网络结构,提取flicker8K数据集中所有的图像特征,利用字典保存,key为文件名(不带.jpg后缀),value为一个网络的输出
- 将字典保存为features.pkl文件(使用pickle库)
理想网络模型
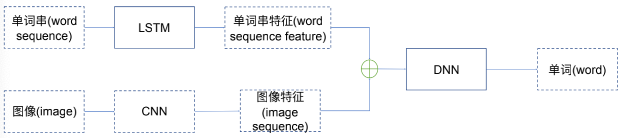
简化网络模型
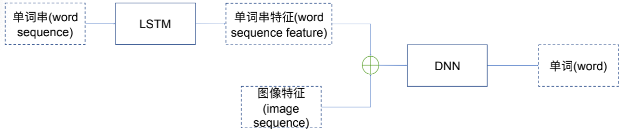
从图像到特征

迁移学习(transfer learning)
- VGG16 CNN原本的目标是分类,基于ImageNet数据集进行训练,训练所需的时间比较大,需要4个GPU训练3星期左右
- 可以调整VGG16的网络结构为图像标题生成服务
- VGG16最后一层是将倒数第二层4096纬的输出转为1000纬的输出作为1000类别的分类概率
- 我们可以通过去除最后一层,将倒数第二层的4096纬的输出作为图像标题生成模型的图像特征
代码实现
1 | from keras.models import model_from_json |



